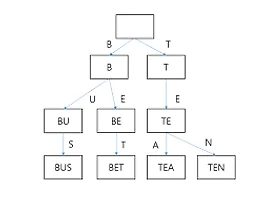
Algorithm/String (4) 썸네일형 리스트형 Labin-Karp 알고리즘 Labin-Karp 알고리즘 이란? 라빈카프 알고리즘이란 이전에 계산한 T[i, i+M-1] 부분 문자열의 해시 값을 이용해서 T[i+1, i+M]의 해시값을 빠르게 구하는 알고리즘이다 구체적인 내용은 이전 KMP 알고리즘을 소개할 때 했으므로 넘어가겠다. 아래는 라빈카프를 활용한 문제풀이이다. 이 문제의 핵심은 두번 이상 등장하는 부분 문자열중 가장 길이가 긴 것을 구해야 하므로 부분 문자열의 길이가 모두 상이 하므로 이분탐색으로 임의의 K를 찾아나가며 가장 긴 길이를 구하는 방식으로 해야한다. 탐색을 하면서 가능한 모든 위치에서 길이 mid인 부분 문자열의 해시값을 구해, 해시값이 충돌했다면 같은 문자열이 앞에 등장했는지 모두 비교를 하고, 아니라면 현재 문자열의 첫 인덱스를 해시에 저장하고 계속 진.. TRIE 자료구조를 사용한 문자열 검색 Trie 자료구조란? 다음과 같이 여러 문자열 사전을 저장하는 트리 형태의 자료구조 이다. Trie에 텍스트 T의 모든 접미사를 저장한다고 하면 O(M)만에 패턴 P를 찾을 수 있다. 다음은 Trie 구조에 전화 번호 목록을 저장해 탐색해가며 일관성 여부를 출력하는 문제와 코드이다. # BOJ 5052:전화번호 목록 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include #.. KMP 알고리즘 주로 문자열 관련 패턴을 찾는 알고리즘으로 대표적인 2가지가 있다. 바로 Hashing에 기반한 Rabin-Karp 알고리즘과 KMP알고리즘이다. Rabin-Karp알고리즘은 해시를 사용해 두 문자열의 해시 값을 구해 이둘을 비교하는 방식으로 오차를 감안하고 찾는다. 해시 값이 다르면 두 문자열은 100% 다르다는 것이지만, 해시값이 같다면 두 문자열은 같을 수 도 있다는 점에서 정확도가 100%가 아니다. 대신, 이전 계산한 부분 문자열의 해시값을 이용해 현재 해시값을 빠르게 구할 수 있기 때문에 탐색 속도가 빠르다. 대표적인 공식은 다음과 같다. 길이가 M인 패턴 P=p1*p2*p3*....pm에 대해 f(p1)=p(m)+p(m-1)*a+p(m-2)*a^2+....p(1)*a^m-1 f(p2)=p(m.. Suffix Array & LCP 알고리즘 Suffix Array에 접미사들을 저장하고, Counting Sort로 정렬해주었다. # Counting Sort는 O(N)시간 복잡도를 가지며, 주로 문자열을 다룰 때 (26개의 알파벳) 주로 사용된다. Quick Sort가 O(NlogN) 복잡도를 가지는 것에 비해서는 매우 짧지만, 같은 패턴이 나오는 문자의 길이가 길어질 수록 Counting Sort도 비효율적이다. Suffix Array를 구성하고 이를 활용해 LCP를 구성한다. # LCP (Longest Common Prefix) : 접미사 배열에서 i번째 접미사와 i-1번째 접미사 사잉서 일치하는 접두사의 길이 LCP 알고리즘을 사용하는 이유는 이전에 비교했던 결과를 최대한 이용해서 i번째 접미사를 비교할 때, i-1번째 접미사에서 비교한 .. 이전 1 다음